Analyzing the potential of pre-trained embeddings for audio classification tasks
Abstract
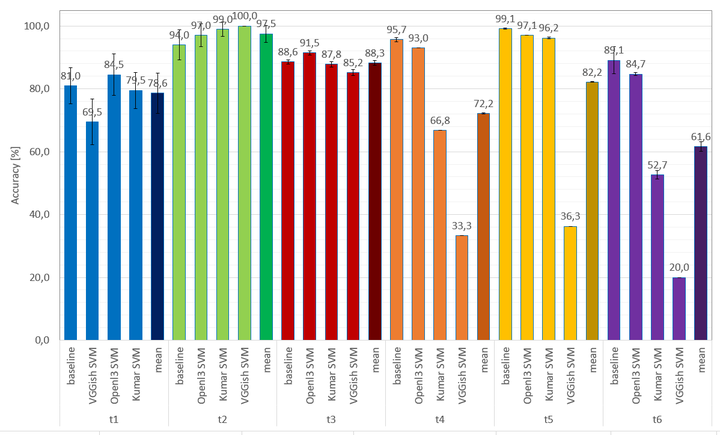
In the context of deep learning, the availability of large amounts of training data can play a critical role in a model’s performance. Transfer learning has shown to be a powerful method in which models are first pre-trained for a task where abundant data is available, and then fine-tuned for a separate task where only a limited amount of data exists. In the past years, several models for audio classification have been pre-trained in a supervised or self-supervised fashion to learn complex feature representations, so called embeddings. These embeddings can then be extracted from smaller datasets and used to train subsequent classifiers. In the field of audio event detection (AED) for example, classifiers using these features have achieved high accuracy without the need of additional domain knowledge. This paper evaluates three state-of-the-art embeddings on six audio classification tasks from the fields of music information retrieval and industrial sound analysis, and presents a detailed overview of their potential. The embeddings are systematically evaluated by analyzing the influence of classifier architecture, fusion methods for file-wise predictions, amount of training data, and trained domain on classification accuracy. To better understand the effect of pre-training, results are also compared with those obtained with models trained from scratch. On average, OpenL3 embeddings performed best with a linear SVM classifier and for a reduced number of training examples they outperform the initial baseline.
Detailed results can be found in here.