Transfer learning from speech to music: towards language-sensitive emotion recognition models
Abstract
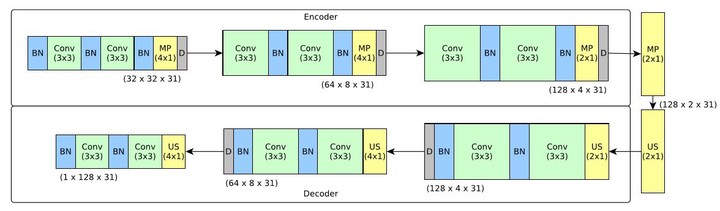
In this study, we address emotion recognition using unsupervised feature learning from speech data, and test its transferability to music. Our approach is to pre-train models using speech in English and Mandarin, and then fine-tune them with excerpts of music labeled with categories of emotion. Our initial hypothesis is that features automatically learned from speech should be transferable to music. Namely, we expect the intra-linguistic setting (e.g., pre-training on speech in English and fine-tuning on music in English) should result in improved performance over the cross-linguistic setting (e.g., pre-training on speech in English and fine-tuning on music in Mandarin). Our results confirm previous research on cross-domain transferability, and encourage research towards language-sensitive Music Emotion Recognition (MER) models.